



呼吸道合胞病毒与流感双重威胁,重点人群如何应对感染风险?
呼吸道传染病高发季
表 1. 第 44 周呼吸道样本主要病原体核酸检测阳性率区域差异

近期活跃的呼吸道合胞病毒、流感病毒有哪些新的动向,哪些人群需要重点防护?
呼吸道合胞病毒,幼儿混合感染危害重
图 1. 杰毅生物呼吸道合胞病毒检出频率
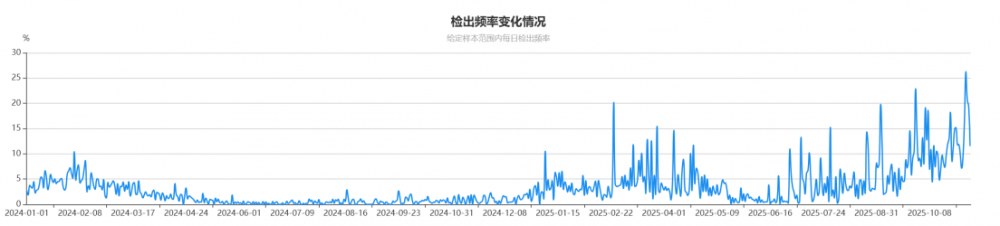
重症呼吸道合胞病毒感染可导致严重并发症,包括心血管及神经系统并发症,包括心力衰竭、脑炎等。越来越多的研究从不同角度揭示,婴儿期呼吸道合胞病毒感染可对呼吸系统带来损伤,甚至持续到成年时期。如患儿出现严重症状,如呼吸急促、呼吸困难和持续高烧不退,应及时就医,及早诊断,避免延误治疗。
杰 Sir TIPS:
1. 目前国内外尚无用于婴儿的针对 RSV 感染的疫苗上市。我国目前批准了 RSV 单克隆抗体,通过被动免疫方式来保护婴幼儿降低感染风险。
流感来袭,新毒株传播范围更大
图 2. 杰毅生物流感病毒病毒检出频率
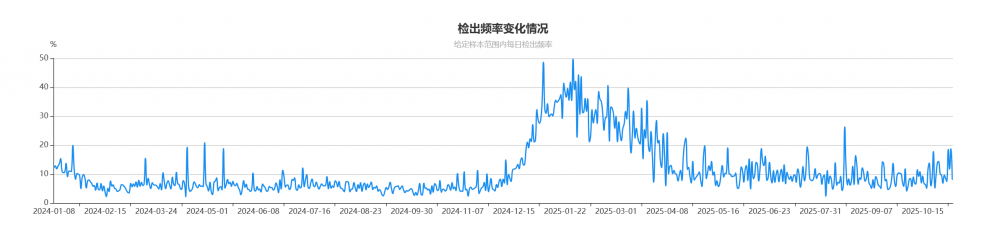
表 2. 流感样病例监测实验室检测结果
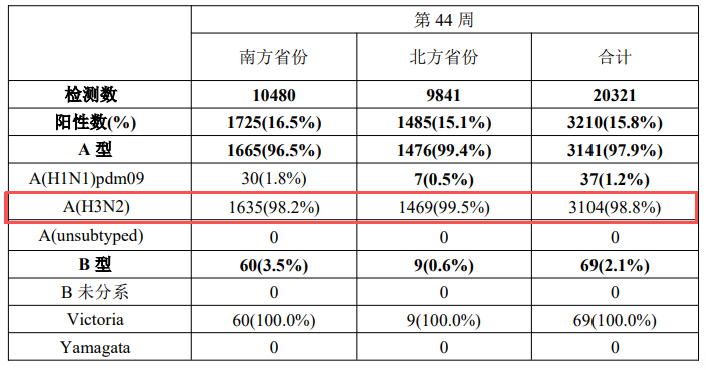
从易感人群来看,H1N1 在年轻成人及肥胖患者中引发重症的风险较高;H3N2 则对老年人与儿童的影响更为显著。研究显示儿童感染 H3N2 后,除高热外,发热持续时间可能更长,且更易继发支气管炎、肺炎等并发症。
杰毅生物精准快速病原体检测、实时监测方案
呼吸道传染病的高发期,多种病原体共循环已成为新常态。发热、咳嗽等症状的病因复杂多样。常规检测方法难以覆盖全部病原体,极易造成漏检。一次性精准筛查数百种常见流行病原体的 tNGS 技术,成为明确病因的高效检测方法。杰毅生物 SeqPlex®tNGS 呼吸采用多重扩增酶切法建库, 对常见及重点关注的呼吸系统感染相关的 324 种病原核酸进行靶向扩增富集, 结合高通量测序技术, 实现对呼吸系统感染病原体广谱精准检测,助力临床提高诊断效率。


为医疗机构 NGS 本地化运营打造的 “毅达 Lab” 数智化实验室信息系统,引入 AI 智能审核,确保每一份报告的及时性和准确性。多维度数据看板则将复杂数据转化为清晰洞察,可实时掌握病原动态,精准预警潜在风险,真正实现病原数据的可知、可控、可预测。






